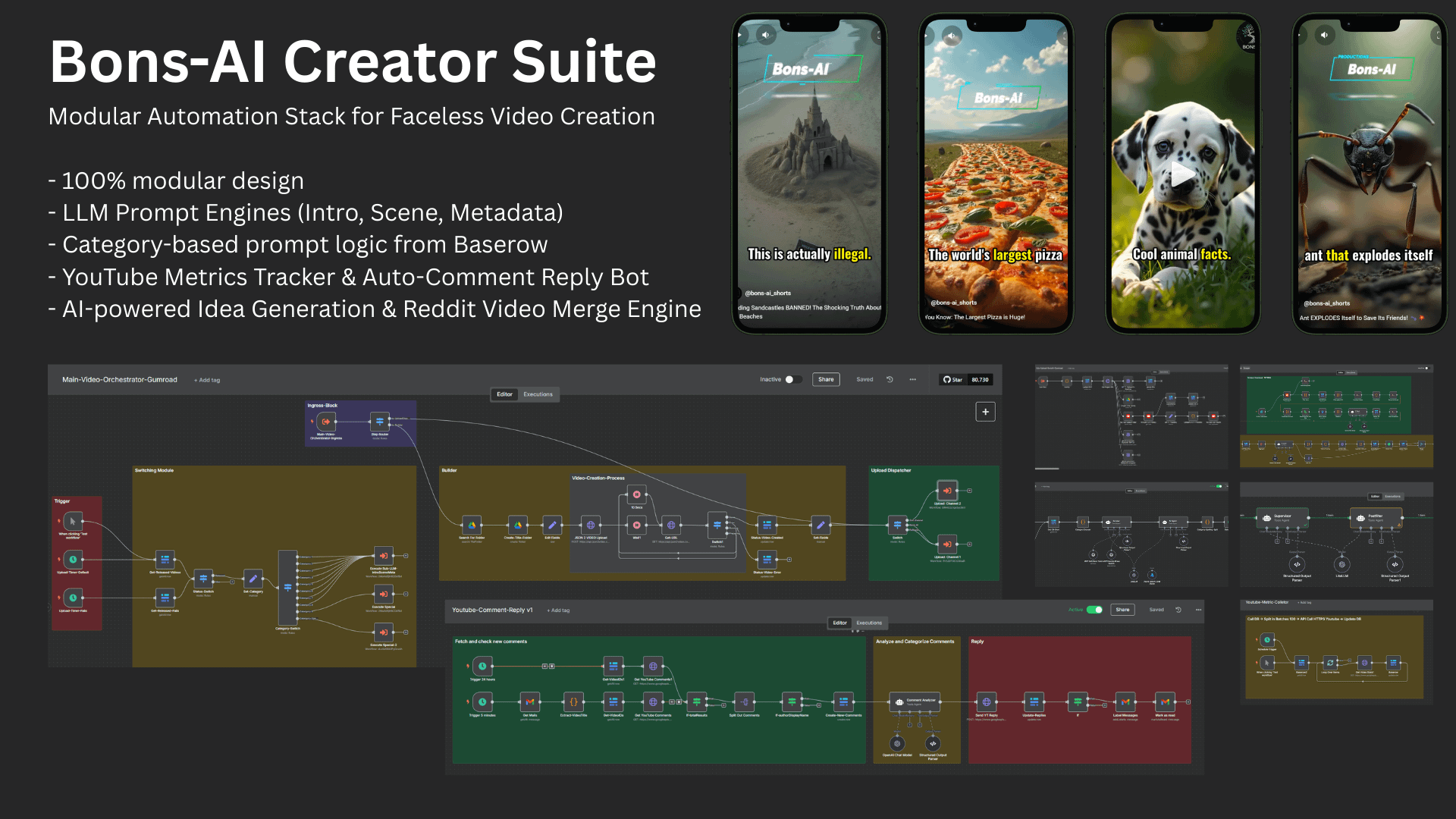
AI视频生成的工业化演进与底层逻辑
AI视频生成正从简单的Demo展示转向工业级生产力。其核心是通过扩散模型(Diffusion Models)与Transformer架构将指令转化为动态像素,目前的进化方向集中在物理模拟、长时长一致性和精准局部编辑。到2026年3月,行业竞争的焦点已转移至算力成本、版权合规及工作流集成。
AI视频的底层逻辑已发生迁移

新一代模型正从“概率预测”转向“物理模拟”。早期模型依赖潜空间随机采样,常导致肢体融合等“幻觉”现象。而Sora 2和Kling 2.6等新一代模型引入的时空注意力机制,使其能模拟基础三维物理规律,而非单纯预测下一帧图像。这种能力的提升让初级剪辑师面临压力,但专业导演的痛点依然是缺乏对镜头语言的绝对控制权,随机生成的“惊喜”无法满足严苛的商业需求。
主流工具的功能分化与适用场景
目前的AI视频工具已形成明显的功能梯队,创作者需根据具体业务场景选择合适的模型。
| 工具名称 | 核心优势 | 最佳适用场景 | 潜在局限 |
|---|---|---|---|
| Sora 2 | 光影折射、复杂流体 | 视觉冲击力大片 | 算力成本高 |
| Kling 2.6 / Wan 2.6 | 面部稳定性极强 | 广告投放、人物特写 | 复杂物理交互偶有失效 |
| Nano Banana Pro | 生成速度快 | 自媒体快节奏内容 | 精细度稍逊 |
| Veo 3 (Google) | 综合指标领先 | 前沿技术探索 | 训练集版权透明度较低 |
商业级可控生成的“三段式”工业工作流
要实现可控生成,建议采用“图像引导 $\rightarrow$ 视频生成 $\rightarrow$ 局部重绘”的三段式工作流。这种方法能最大程度降低AI的随机性,确保最终产出符合导演预期。
避免直接使用文生视频。先在Midjourney或Flux中生成符合电影构图(如三分法)的静态底图,确保光影方向明确。将底图上传至“图生视频”入口,将运动幅度设为3-5(总分10)。Prompt应聚焦于描述“变化”而非描述对象。例如,底图为雨中行人,Prompt应写为“雨滴在角色肩头溅起,背景霓虹灯在积水中产生动态模糊”。
通过涂抹需要位移的区域(如流动的水、飘动的发丝)并指定运动方向与强度,可将AI的随机性降低至20%以下。
在此阶段,应减少全局Prompt中的动词,以免指令冲突。若笔刷边缘出现生硬切割感,建议使用柔边刷并增加“环境融合度”参数,以实现电影级的定格效果。
将前一镜头的最后一帧作为下一段视频的起始图(Start Frame),并在端到端模式下锁定。
利用Luma或Runway的插值工具对衔接处进行0.5秒平滑过渡,并将帧率统一设为24fps。若色调出现偏差,可用达芬奇(DaVinci Resolve)的颜色匹配工具强制同步色阶,从而消除“PPT感”。
成本核算与实操局限性分析
在订阅方案上,建议对比“单次有效产出成本”而非单月价格。2026年1月的数据显示,Higgsfield等提供无限量供应套餐的平台,比采取严格点数制的闭源平台更适合需要大量筛选(抽卡)的创作者。一个成功率仅10%的低价工具,其实际成本远高于成功率50%的高价工具。
目前AI视频仍存在的三个“硬伤”
- 复杂物理交互失效: 如“撕纸”或“液体飞溅”时容易出现物体融合。
- 长程语义一致性不足: 超过30秒的视频中背景细节常会发生微变。
- 版权灰度: 风格高度相似时存在法律风险。
不建议使用AI视频的特定场景
- 需要极致精准动作捕捉的表演(无法传达细腻情绪)。
- 要求螺丝级精准的工业产品演示。
- 需要在极短时间内频繁修改细节的紧急项目(手动K帧效率更高)。
Q:如何有效解决AI视频中出现的肢体扭曲问题?
可以通过降低运动幅度参数,并配合使用“区域重绘”掩码覆盖故障区域进行局部修复。
Q:如何评估一个AI视频工具的实际商业成本?
不应只看月费,而应计算“单次有效产出成本”。计算公式为:月费 ÷ (月度总生成次数 × 成功率)。成功率高的工具即便月费昂贵,其实际生产成本往往更低。
Q:面对AI视频的冲击,创作者应该如何构建竞争力?
重心应从学习软件操作转向培养导演思维,提升审美和叙事能力。最稳健的路径是将AI视频作为B-roll(辅助镜头)与实拍素材结合,而非全盘替代。